1 Introduction to R Markdown
1.1 Introduction
In this chapter, we turn an R script into a fully reproducible R Markdown report using the NYPD Shooting Incident Data from NYC Open Data. We load the dataset through an API, clean and prepare the data, explore patterns, and create tables and visualizations using kable() and ggplot2. The goal is to practice building a clear, reproducible workflow that combines code, narrative text, and results in a single document.
1.3 Data Ingestion via API
Next, we pull the NYPD shooting incident data directly from NYC Open Data using httr::GET() and the endpoint below.
endpoint <- "https://data.cityofnewyork.us/resource/833y-fsy8.json"
resp <- httr::GET(endpoint, query = list("$limit" = 30000, "$order" = "occur_date DESC"))
shooting_data <- jsonlite::fromJSON(httr::content(resp, as = "text"), flatten = TRUE)This request returns up to 30,000 records, sorted from newest to oldest by occur date. The dataset covers incidents from 2006-01-01T00:00:00.000 to 2024-12-31T00:00:00.000.
1.4 Cleaning Data
Now that the dataset was successfully loaded, we began the data cleaning process.
1.4.1 Removing NA rows in perp_race
## incident_key occur_date occur_time
## 0 0 0
## boro loc_of_occur_desc precinct
## 0 25596 0
## jurisdiction_code loc_classfctn_desc location_desc
## 2 25596 14977
## statistical_murder_flag perp_age_group perp_sex
## 0 9344 9310
## perp_race vic_age_group vic_sex
## 9310 0 0
## vic_race x_coord_cd y_coord_cd
## 0 0 0
## latitude longitude geocoded_column.type
## 97 97 97
## geocoded_column.coordinates
## 0## [1] 9310# Remove rows where perp_race is missing or marked as unavailable
shooting_clean<-shooting_data %>% filter(
!is.na(perp_race) &
!(perp_race %in% c("(NULL)","UNKNOWN","(null)")))
# Confirm that missing values were removed
sum(is.na(shooting_clean$perp_race))## [1] 0Here, we check how many missing values are present across the dataset. We then focus on the perp_race column, which originally contains 9310 missing values. After filtering out rows with missing or unavailable values, we check the column again to confirm that the cleaning step is successful.
1.4.2 Making perp_race Values Lowercase
Next, we standardize the perp_race column by converting all values to lowercase. This prevents duplicate categories that differ only by capitalization.
1.4.3 Creating a time_of_day Column
After some initial cleaning and standardizing, we now create a new column called time_of_day that groups each incident into broader time categories.
# Split occur_time into Hour, Minute, and Second
shooting_clean<- shooting_data %>% separate(
col = occur_time,
into = c("Hour","Minute","Second"),
sep = ":",
)
# Create a time_of_day category based on the Hour value
shooting_clean <- shooting_clean %>% mutate(
time_of_day = case_when(
Hour < 12 ~ "Morning",
Hour < 18 ~ "Afternoon",
Hour >= 18 ~ "Night"
))To create the time_of_day column, we first split the occur_time variable into separate Hour, Minute, and Second columns. Then we group the Hour values into three categories: Morning, Afternoon, and Night. The number of shootings in each group is ; Morning Afternoon Night ; 12222 5439 12083 .
1.5 Insights
1.5.1 Time of Day
Next, we summarize how often shootings occur during each time of day.
## [1] "incident_key" "occur_date"
## [3] "Hour" "Minute"
## [5] "Second" "boro"
## [7] "loc_of_occur_desc" "precinct"
## [9] "jurisdiction_code" "loc_classfctn_desc"
## [11] "location_desc" "statistical_murder_flag"
## [13] "perp_age_group" "perp_sex"
## [15] "perp_race" "vic_age_group"
## [17] "vic_sex" "vic_race"
## [19] "x_coord_cd" "y_coord_cd"
## [21] "latitude" "longitude"
## [23] "geocoded_column.type" "geocoded_column.coordinates"
## [25] "time_of_day"# Count shootings by time of day in descending order
shooting_clean %>% count(time_of_day)%>% arrange(desc(n))## time_of_day n
## 1 Morning 12222
## 2 Night 12083
## 3 Afternoon 5439# Count shootings by time of day and borough in descending order
shooting_clean %>% count(time_of_day,boro) %>% arrange(desc(n))## time_of_day boro n
## 1 Night BROOKLYN 4793
## 2 Morning BROOKLYN 4554
## 3 Night BRONX 3761
## 4 Morning BRONX 3517
## 5 Afternoon BROOKLYN 2338
## 6 Morning QUEENS 2072
## 7 Morning MANHATTAN 1709
## 8 Night MANHATTAN 1648
## 9 Night QUEENS 1575
## 10 Afternoon BRONX 1556
## 11 Afternoon QUEENS 779
## 12 Afternoon MANHATTAN 620
## 13 Morning STATEN ISLAND 370
## 14 Night STATEN ISLAND 306
## 15 Afternoon STATEN ISLAND 146# Create a summary table with counts and percentages for each time of day category
time_summary <- shooting_clean %>%
filter(!is.na(time_of_day)) %>%
count(time_of_day, name = "n") %>%
mutate(pct = round(100 * n / sum(n), 1)) %>%
arrange(desc(n))
time_summary## time_of_day n pct
## 1 Morning 12222 41.1
## 2 Night 12083 40.6
## 3 Afternoon 5439 18.3We count incidents in the Morning, Afternoon, and Night and arrange them from highest to lowest. The highest rate occurs during Morning (12222 cases; 41.1%).
1.5.2 Sex of Perpetrator
We also summarize the distribution of perpetrator sex.
## [1] "incident_key" "occur_date"
## [3] "Hour" "Minute"
## [5] "Second" "boro"
## [7] "loc_of_occur_desc" "precinct"
## [9] "jurisdiction_code" "loc_classfctn_desc"
## [11] "location_desc" "statistical_murder_flag"
## [13] "perp_age_group" "perp_sex"
## [15] "perp_race" "vic_age_group"
## [17] "vic_sex" "vic_race"
## [19] "x_coord_cd" "y_coord_cd"
## [21] "latitude" "longitude"
## [23] "geocoded_column.type" "geocoded_column.coordinates"
## [25] "time_of_day"# Remove missing and unavailable perp_sex values
shooting_clean_sex <- shooting_clean %>%
filter(!is.na(perp_sex),
!(perp_sex %in% c("U","(null)")))
# Count shootings by perpetrator sex and borough in descending order
shooting_clean_sex %>% count(perp_sex,boro)%>% arrange(desc(n))## perp_sex boro n
## 1 M BROOKLYN 5971
## 2 M BRONX 5279
## 3 M QUEENS 2502
## 4 M MANHATTAN 2484
## 5 M STATEN ISLAND 609
## 6 F BROOKLYN 146
## 7 F BRONX 134
## 8 F MANHATTAN 87
## 9 F QUEENS 79
## 10 F STATEN ISLAND 15# Count male perpetrators by borough (after removing missing boroughs)
male_by_boro <- shooting_clean_sex %>%
filter(perp_sex == "M", !is.na(boro)) %>%
count(boro, name = "n") %>%
arrange(desc(n)) %>%
mutate(boro = str_to_title(boro))
male_by_boro## boro n
## 1 Brooklyn 5971
## 2 Bronx 5279
## 3 Queens 2502
## 4 Manhattan 2484
## 5 Staten Island 609We clean the perp_sex variable by removing missing and unavailable values. Then, we count how many shootings involved each sex in each borough. After that, we focus on male perpetrators and summarize the number of male-involved incidents by borough. The borough with the highest number of male perpetrator incidents is Brooklyn (5971 cases; 35.4%).
1.6 Tables & Graphs
1.6.1 Table (kable)
Now that we have an overview of our data, we create a table to neatly display a portion of the cleaned dataset.
# Filter out missing or unavailable perpetrator sex values
shooting_top <- shooting_clean %>% filter(!is.na(perp_sex), !(perp_sex %in% c("U","(null)"))) %>%
# Convert occur_date to a Date format
mutate(occur_date = as.Date(str_remove(occur_date, "T.*")),
# Recode perpetrator sex labels for readability
perp_sex = case_when(
perp_sex == "M" ~ "Male",
perp_sex == "F" ~ "Female",
TRUE ~ perp_sex)) %>%
# Select key columns using base R indexing and display the first 10 rows
.[, c("occur_date", "boro", "time_of_day", "perp_sex", "perp_race")] %>%
dplyr::slice_head(n = 10)
# Display the cleaned preview table
shooting_top## occur_date boro time_of_day perp_sex perp_race
## 1 2024-12-31 BROOKLYN Night Male BLACK
## 2 2024-12-31 BROOKLYN Night Male BLACK
## 3 2024-12-30 BRONX Afternoon Male BLACK
## 4 2024-12-30 BROOKLYN Night Male BLACK
## 5 2024-12-30 BRONX Night Male BLACK
## 6 2024-12-29 BRONX Afternoon Male BLACK
## 7 2024-12-28 MANHATTAN Night Male BLACK
## 8 2024-12-28 MANHATTAN Night Female BLACK
## 9 2024-12-27 BRONX Night Male BLACK HISPANIC
## 10 2024-12-27 BRONX Night Male BLACK HISPANIC# Identify the most common perpetrator sex in the dataset
top_sex <- shooting_top %>% count(perp_sex, sort = TRUE) %>% slice(1)
# Create a kable table
kable(shooting_top,
caption = "Preview of 10 cleaned NYPD shooting records showing the date, borough, time of day, perpetrator sex, and perpetrator race. This table provides a quick view of the variables used in the analysis after cleaning.") | occur_date | boro | time_of_day | perp_sex | perp_race |
|---|---|---|---|---|
| 2024-12-31 | BROOKLYN | Night | Male | BLACK |
| 2024-12-31 | BROOKLYN | Night | Male | BLACK |
| 2024-12-30 | BRONX | Afternoon | Male | BLACK |
| 2024-12-30 | BROOKLYN | Night | Male | BLACK |
| 2024-12-30 | BRONX | Night | Male | BLACK |
| 2024-12-29 | BRONX | Afternoon | Male | BLACK |
| 2024-12-28 | MANHATTAN | Night | Male | BLACK |
| 2024-12-28 | MANHATTAN | Night | Female | BLACK |
| 2024-12-27 | BRONX | Night | Male | BLACK HISPANIC |
| 2024-12-27 | BRONX | Night | Male | BLACK HISPANIC |
We remove rows with missing or unavailable perpetrator sex values, convert occur_date to a date format without the time stamp, and recode sex labels to ‘Male’ and ‘Female’ for readability. We then select key columns and display the first 10 rows of the cleaned dataset. The most common perpetrator sex in this subset is Male.
1.6.2 Graphs (ggplot2)
1.6.2.1 Time of Day Plot
To better understand patterns in the data, we visualize shooting counts by time of day using a bar chart.
shooting_time<- shooting_clean %>%
group_by(time_of_day,boro) %>%
summarize(total=n())
ggplot(shooting_time, aes(x = time_of_day, y = total, fill = time_of_day)) +
geom_col() +
labs(title = "Time of Shootings in NYC",
x = "Time of Day", y = "Number of Shootings",fill="Time of Day") +
theme_minimal(base_size = 12) +
theme(plot.title = element_text(size = 17, family = "Georgia", face = "bold"),
axis.title.x = element_text(size = 12, family = "Georgia"),
axis.title.y = element_text(size = 12, family = "Georgia"))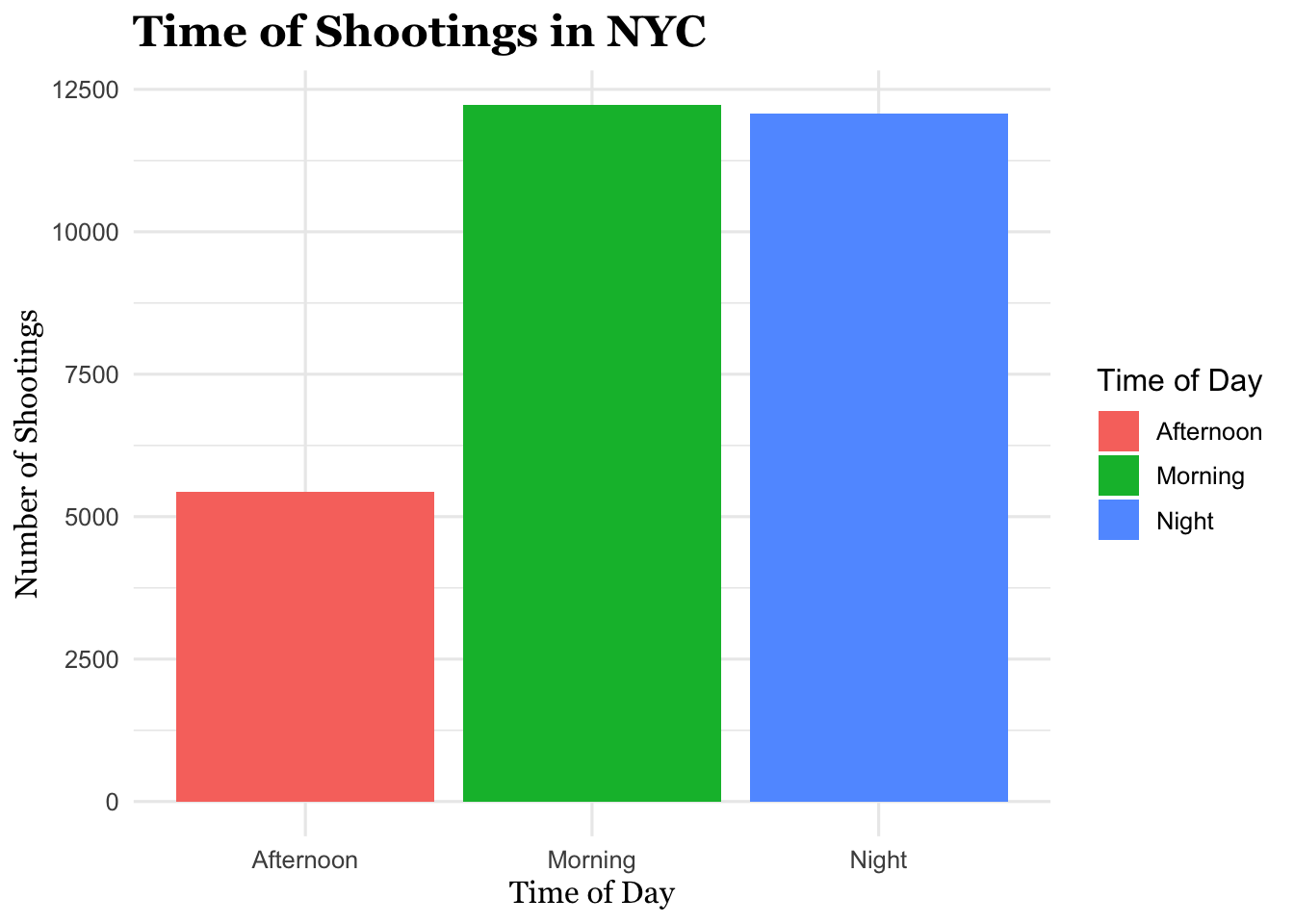
(#fig:time of day plot)Bar chart showing the total number of NYPD shooting incidents by time of day (Morning, Afternoon, Night). This figure helps show how shootings are distributed across the day.
Interpretation: We group shootings by time of day and borough, count the number of incidents, and create a bar chart showing total shootings by time of day. The fewest shooting incidents occur during the Afternoon.
1.6.2.2 Sex of Perpetrator Plot
Next, we visualize the number of shooting incidents by perpetrator sex across boroughs using a faceted bar chart.
shooting_clean_perp_sex<- shooting_clean_sex %>%
group_by(perp_sex,boro) %>%
summarize(total=n())
shooting_clean_perp_sex <- shooting_clean_perp_sex %>%
mutate(
perp_sex = factor(perp_sex, levels = c("F","M"),
labels = c("Female","Male")))
ggplot(shooting_clean_perp_sex, aes(x = perp_sex, y = total, fill = perp_sex)) +
geom_col() +
facet_wrap(~ boro) +
labs(
title = "Shootings by Sex of Perpetrator (Faceted by Borough)",
x = "Perpetrator Sex", y = "Number of Shootings", fill = "Perpetrator Sex"
) +
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(size = 17, family = "sans", face = "bold"),
axis.title.x = element_text(size = 12, family = "sans"),
axis.title.y = element_text(size = 12, family = "sans")
)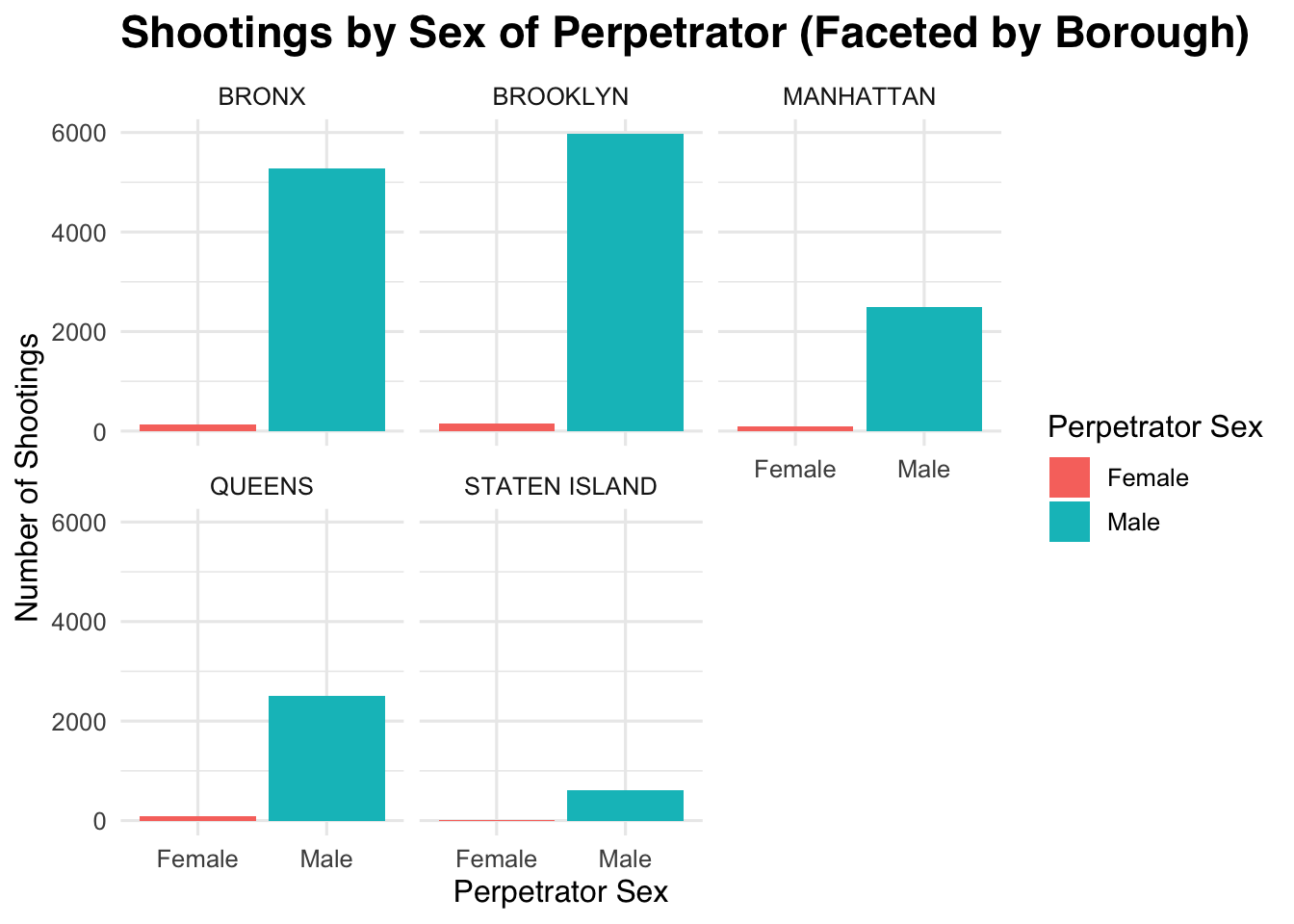
(#fig:sex of perpetrator plot)Bar charts showing the number of NYPD shooting incidents by perpetrator sex, separated by borough. This figure allows for comparison of shooting counts by sex across different boroughs.
Interpretation: We group the data by perpetrator sex and borough, count incidents, and recode sex labels to ‘Female’ and ‘Male.’ We then plot a faceted bar chart showing shootings by perpetrator sex for each borough. The borough with the fewest shootings is STATEN ISLAND (624 incidents).
1.7 Reflection
Learning how to create an R Markdown document will be very helpful when I begin working with my thesis dataset. It allows me to keep my code and explanations organized in a clear, step-by-step workflow, making it easy to see how each part of the analysis was carried out. When I return to the project later, the document serves as a built-in guide that helps me understand my previous decisions and continue the work without confusion. This structure also supports reproducibility and makes it easy to share my workflow with others.